
NAT Behavioral Specifications for p2p applications interoperability
Table of Contents
- Problem statement and introduction
- Glossary
- Peer-to-peer connectivity for hosts behind NATs
- NAT, diagram and terminology
- Protocols to perform NAT traversal, advantages of hole punching
- Hole Punching
- External endpoint prediction
- Hole punching
- The UDP Hole Punching protocol
- External endpoint prediction step
- Hole punching step
- The TCP Hole Punching protocol
- Restrictions on TCP when compared to UDP
- TCP Simultaneous Open
- Port prediction step
- Hole punching step
- Requirements on NATs to support hole punching protocols
- General properties of the port allocation algorithm
- Information and topology preservation
- Regularity
- Formalised Requirements
- Mapping allocation schemes
- Filtering schemes
- UDP mapping refresh
- Support for hairpinning
- Optional
- General properties of the port allocation algorithm
Problem statement and introduction
End-to-end connectivity between hosts is a corner-stone principle for interoperability on the Internet. Hosts must be able to communicate with each other directly.
With the wide deployment of IPv4 NATs, home gateways or carrier grade NATs, the end-to-end connectivity principle may not always be guaranteed. Without some cooperation of the NATs, hosts cannot always communicate with each other directly.
To make communication between hosts behind NATs easier, a NAT should follow some behavioral rules. NAT do not necessarily break end-to-end connectivity, and good NAT behavior guarantees that hosts behind NATs will be able to communicate directly. The purpose of this document is to describe these rules and their rationale.
The first part of this document – Peer-to-peer connectivity for hosts behind NATs – explains the rationale behind the requirements and provides boilerplate background information about the hole punching protocols. We provide a detailed description of the different ways to perform TCP hole punching.
The second part of this document – Requirements on NATs to support hole punching protocols – lists recommendations for NAT behaviors to ensure interoperability with p2p applications.
Glossary
NAT device: a device that has two network addresses and perform translation between the two when network packets go through
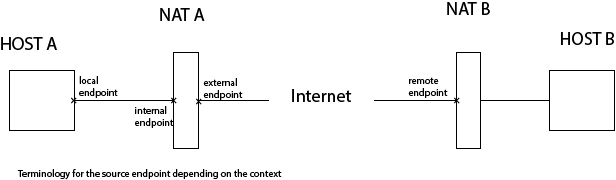
local endpoint: the source endpoint from the application point of view / from the NAT point of view
internal endpoint: the source endpoint from the NAT point of view
public mapping / external mapping / external endpoint: the source endpoint after translation from the NAT point of view
remote endpoint: the destination endpoint from the application point of view
communication: a communication is uniquely identified by the triple {protocol, local endpoint, remote endpoint}. A packets belongs to one and only communication.
session: a session is uniquely identified by the 5-uple {protocol, local endpoint, remote endpoint, start time of the communication, end time of the communication}. UDP does not have the notion of session, TCP does. If needed, sessions in UDP are multiplexed and implemented by the application.
Peer-to-peer connectivity for hosts behind NATs
NAT, diagram and terminology
The diagram below give the relations in a network between NATs and hosts, and endpoints terminology:
Protocols to perform NAT traversal, advantages of hole punching
- UDP Hole Punching
- TCP Hole Punching (using TCP simultaneous open)
- UPnP, NAT-PMP and other proprietary protocols to open and forward ports in NATs
- Static port-forwarding
We focus in this document on hole punching protocols. Other methods are also widely used, however they are out of scope of this document and are generally considered to have undesirable properties for peer-to-peer applications and from a network security point of view. They amount to mapping internal endpoints to external ports statically. Such methods invariably have scalability issues when the number of subscribers increases, as collisions between mappings may occur more frequently. They also require hosts to have a fixed listening socket and need the NAT to maintain static mappings for the whole lifetime of the application, increasing the application footprint and its use of scarce resources on the NAT side. Only hole punching is a peer-to-peer technique that does not require port forwarding. With hole punching, a mapping only need to exist for the duration of each session, making an optimal use of NAT resources.
Hole punching also does not require the application to have a listening socket (for TCP), thus there is no need to use the “accept()” and “listen()” POSIX calls and no need to ask the operating system for elevated rights. Listening on sockets increases the application footprint by making a perpetual use of a scarce resource on the host side. Some operating systems, firewall and antivirus also restrict these calls and prompt the user for elevated rights to be granted to the application. Good practice for TCP sockets dictates that non-privileged clients should not listen on sockets, should not explicitly bind on sockets when they only make outgoing TCP connections, and should leave the local endpoint selection for each socket to the OS by doing implicit binding, the OS binding the socket to a port in the ephemeral port range.
Hole Punching
We describe here hole punching protocols in general.
NAT traversal through hole punching will necessarily happen in two steps. The first step is predicting/discovering the external endpoint of the counterpart and acquiring this information over an arbitrary out-of-band channel. The second step is the hole punching mechanism to establish the communication through the NATs. These steps are explained below.
External endpoint prediction
NATs introduce an additional layer of complexity when it comes to achieving end-to-end connectivity. NATs map a local source endpoint to a a-priori unknown external source endpoint. Applications behind NATs typically do not have the information of this mapped external endpoint. When two hosts are behind NATs, they will need to learn each other remote endpoints before they can initiate a communication.
For protocols that uses ports, like UDP or TCP, most of the difficulty comes from predicting or discovering the external port allocated by the NAT to a given session. To achieve port prediction and end-to-end connectivity, NATs will need to allocate mappings in some predictable way, in a sense that will be defined in the sections below or later at section [General properties of the port allocation algorithm], so applications can perform port prediction/discovery.
Performing external port prediction/discovery
In this section we introduce port prediction/discovery. This is a necessary step of the hole punching process and it can be done in a variety of ways. We can’t list them all here, we give instead a classification of these methods and what type of properties of the NAT each of them is relying upon.
External port discovery may be done with or without the help of an address discovery server. An address server will be external to the NAT and publicly accessible. This address server will provide information about their external endpoint to the hosts. It seems that using an address server to initiate a peer-to-peer communication goes against the end-to-end connectivity principle, and in the context of decentralized peer-to-peer networks, such servers are not available. It is often preferable to use a method that does not need a third party address server. Nevertheless, some applications may want to use such third party address servers in the hole punching process.
Below we describe informally these general methods to perform port prediction, with or without the help of an address server. Each of these methods rely on some regularity properties of the NAT mapping allocation algorithm. These methods are applicable to any protocol that uses ports, such as UDP and TCP. In later sections, we describe the port prediction and hole punching steps in more details for each of these protocols.
With an address server:
In the context of an address server and if supported by the NAT, we can rely on some of the following properties of the NAT allocation algorithm to perform port prediction:
- successive sessions from the same local endpoint are mapped to the same external endpoint
- successive sessions from consecutive local endpoints are mapped to consecutive external endpoints.
By “successive sessions”, we mean sessions happening within a short timeframe, typically within a few seconds. Property (1) is often preferred by applications as it is significantly simpler to use and such property can often be granted by the NAT. Property (1) can always be granted when the NAT does not use port overloading. When it does, collisions between mappings may occur in which case the NAT will choose another port, violating Property (1) for this session. This short list of usable properties is not exhaustive, any regularity property exposed by the NAT for successive mappings can be exploited by the application to perform port prediction.
We can leverage such properties of the NAT and use an address server to perform port prediction. For UDP, address servers are often called STUN servers. They will typically be publicly accessible and have a listening socket. Port prediction/discovery with an address server will happen as follows:
- each host sends a packet to the address server
- upon receipt of a packet from a host, the server learns the host external endpoint for this session
- such information is shared with all relevant parties
- hosts can then use this information and some regularity properties of the NAT mappings allocation algorithm to make guesses about subsequent mappings.
For example, if the NAT uses endpoint-independent mapping, subsequent sessions from the same local endpoint will use the same external endpoint. If an application knows that the NAT follows such behavioral rule, it is easy for an application to predict the external port of certain mappings.
Without an address server:
There are other ways to predict the external mapping without relying on a public address server. When the NAT has one of the following properties, an address server becomes unnecessary:
1. NAT uses an endpoint-independent mapping scheme, ie the NAT reuses the same mapping for all packets originating from the same local endpoint (the NAT “maps a cone to a cone”). The corresponding network flows must be simultaneous or occur within a short timeframe, such as 2 minutes.
For non-connected sockets, like UDP, the POSIX system calls let the application use the same socket (and thus, the same local endpoint) to communicate with different remote endpoints by using the recvrom() and sendto() calls. (The same cannot be done for connected socket such as TCP as explained in section [Restrictions on TCP when compared to UDP]). In that case the port discovery mechanism need only to be done once in the lifetime of the UDP socket (which can be the lifetime of the application). An application will use an address server for its first-ever peer-to-peer communication, learn and/or share the information of the mapping and then reuse the same socket for all subsequent communications.
2. NAT uses a port preserving mapping scheme, ie the NAT maps an internal source port number to the same external source port number. This can be done if the resulting 3-tuple (made of the source endpoint) is unique or in case the NAT supports port overloading, if the 5-tuple is unique.
In that case, a host has immediately the information of the external port: it is the same as the internal port. This regularity property is especially useful for connected sockets like TCP, since an application cannot use the previous method by multiplexing communications over the same sockets, as explained in section [Restrictions on TCP when compared to UDP]. For non-connected sockets like UDP, this property is not necessary, and Property 1. is generally preferred.
Other methods relying on other regularity properties of the NAT allocation algorithm may be used for port discovery without an external server, like when the NAT allocation scheme is “port delta preserving” (the mappings of two successive sessions preserves the difference between the internal ports numbers).
Sharing the external port information
Once the external mapping port information is discovered or can be predicted, it can be shared with the relevant hosts through an arbitrary out-of-band communication channel. For example, a STUN server or an overlay network may be used as a communication channel to share the external port information.
Once these steps are completed, the hosts are ready to perform hole punching.
Hole punching
Assuming both hosts behind NATs can predict or discover their counterpart’s external endpoint, they are still unable to communicate to each other directly since the NAT/firewall will generally deny incoming packets that are not part of an already established communication. This is the role of hole punching to establish a communication from the NAT viewpoint so that packets can finally go through. The mechanism is as follows:
- Host A or Host B (or both) sends an initial packet to its counterpart’s external endpoint
- As one NAT (or both) sees an outgoing packet originating from an internal host, it creates the relevant state and mapping in its table for this communication
- Incoming packets for this communication will now be allowed through and mapped to the internal host, which means the communication is established
Hole punching relies on the NAT passively dropping packets that do not belong to a previously established communication. If the NAT actively denies the packet (by sending an ICMP packet, by sending an RST segment, by cancelling a previously established communication on the same mapping, etc.), it may confuse the protocol stack and negatively interfere with communication establishment.
The UDP Hole Punching protocol
UDP hole punching will happen exactly as above.
External endpoint discovery step
The external endpoint discovery step can be performed by both hosts sending UDP packets to an address server (commonly named a STUN server) and learning their respective external mappings.
It can also be performed without an address server, by reusing the same socket and sharing the previously learnt external mapping with the other host through an arbitrary communication channel.
Hole punching step
Once peers have shared the information of each other external endpoints, they can punch holes in their NAT and establish a UDP communication session.
- application sends a packet to the remote host on the predicted remote external endpoint
- the NAT “opens a hole” for this 5-tuple
- application can now send or receive packets to the remote host
Once this steps have been completed, the communication is established.
The TCP Hole Punching protocol
Restrictions on TCP when compared to UDP
TCP has a few restrictions compared to non-connected protocols such as UDP. Some restrictions come from the protocol itself, others from the POSIX API to the protocol.
TCP sessions cannot be multiplexed over the same socket
As opposed to non-connected socket, the POSIX API does not support multiplexing multiple sessions on connected sockets. An application is restricted to use the recv() and send() POSIX functions for TCP sockets, whereas for UDP it can also use the recvfrom() and sendfrom() functions.
In other words, one TCP socket can only support one TCP session.
An application cannot use the same local endpoint for two simultaneous TCP sessions
This is a general POSIX requirement that two sockets cannot bind to the same local endpoint. In the POSIX specification, System Interfaces, bind(), we have: “The bind() function shall fail if: [EADDRINUSE] The specified address is already in use.”
To bypass this constraint, we could use a “hack” by using the SO_REUSADDR option on the sockets. Although this option was initially intended to be use with IP multicasting, it has other interesting uses as side effects, such as allowing multiple TCP sockets to bind to the same local endpoints. Unfortunately, for TCP this leads to additional complications. This is explained in more details in the next section. For example, reusing the same local endpoint for all TCP sockets would defeat port randomization, and leave TCP vulnerable to blind attacks as described in RFC 6056.
An application cannot reuse the same local endpoint for two successive TCP sessions
Usage of distinct ephemeral ports for distinct outgoing TCP connections is generally good practice, but there are additional constraints from TCP enforcing this behavior.
After a TCP connection is closed, the local endpoint of the peer that initiated the active close will be in the TIME_WAIT state. This will generally be the case when closing a connection to a server, since the application doesn’t want the TIME_WAIT state to sit on the server and accumulate over there, and thus the client will perform the active close and get the TIME_WAIT. For peer-to-peer communications, there is no preference of which host would get the TIME_WAIT.
The host that has the TIME_WAIT state will not be allowed by the OS and for a certain period of time to bind another socket on this local endpoint. A POSIX EADDRINUSE error will be returned by the bind() system call: local endpoints that have a TIME_WAIT state attached to them cannot be reused for another TCP connection as specified in RFC0793. This requirement is here to avoid receiving stale TCP segments of an old session on the same 5-tuple.
This requirement is relayed in various RFCs, for example: RFC1323, page 27 (appendix B.2), quoting: “Applications built upon TCP that close one connection and open a new one (…) must choose a new socket pair each time.” (note that the application does not have always have the choice, as when the TIME_WAIT is sitting on its side, it has to bind to a new local endpoint, as the OS won’t allow binding to the previous one).
The TIME_WAIT state can also be bypassed by using the SO_REUSEADDR option, as explained in the next section.
Bypassing the two previous constraints by using SO_REUSEADDR
These additional constraints of TCP can be bypassed by the application by using a “hack”, that is by setting the SO_REUSEADDR option on all sockets. The original intent of this option is for IP multicasting, but it has other interesting side effects on may operating systems. What this option really does is not specified by POSIX, instead POSIX delegates the specification to the underlying protocol; from the POSIX specification:
“SO_REUSEADDR Specifies that the rules used in validating addresses supplied to bind() should allow reuse of local addresses, if this is supported by the protocol. ”
On many operating systems, including Windows, Linux, BSD, setting this option on TCP sockets has two consequences, among others:
- it allows the application to bind two sockets to the same local endpoint. This is the first point of interest. However, this scheme is not as broadly applicable as with UDP, where one can use the same socket (and thus the same local endpoint) for all communications: it is not possible to connect to the same remote endpoint using the same local endpoint, as it would create a 5-tuple duplicate. Consequently, it is not possible to use the same local endpoint for all TCP communications.
- it allows the application to bind to a local endpoint in the TIME_WAIT state. This allows applications to bind successive TCP sockets to the same local endpoint and bypass the TIME_WAIT state. For example, such behavior may be useful for restarting listening servers so one does not have to wait for the TIME_WAIT timer to elapse before being able to bind their listening socket. Of course, bypassing the TIME_WAIT state is not compliant with TCP. In which case the server will need to be prepared to deal with the hazards that come with TIME_WAIT assassination. Such method should generally not be used for making outbound TCP connections, but such “hack” is available to applications nonetheless.
Usage of the SO_REUSEADDR in our context comes with the following concerns, which makes its use fatally flawed for a large range of applications:
- it is not portable. The behavior of this option is not specified by POSIX
- the connect() system call may now fail in a new scenario, when the application makes multiple connections from the same local endpoint to the same remote endpoint (same 5-tuples). This error case is not specified by POSIX. Such case would not arise if distinct sockets bind to distinct local endpoints, as required by POSIX.
- not compliant with TCP. TIME_WAIT assassination can lead to data corruption, especially for some p2p applications that consume TCP sessions at a high frequency. See also RFC 1337.
- the application does not use ephemeral ports randomized by the OS anymore since it binds sockets explicitly. The security implications of this are exposed in RFC 6056.
- local security issues. Any other application on the host can hijack the TCP sockets of the application, regardless of privileges (although such behavior can vary depending on the operating system – none of it being specified in POSIX), and can steal data and cause data corruption
Although usage of SO_REUSEADDR is undesirable from the application viewpoint, it may still be used by an application that is prepared to deal with all its shortcomings to leverage some regularity properties of the NAT allocation algorithm and perform TCP hole punching.
Making a connection to an address server before each p2p connection is undesirable: causes latency and load on the address server
If we need to make a connection to an address server each time we want to perform a peer-to-peer TCP connection, the address server may have to handle a large amount of TCP connections. Each TCP connection consumes a non negligible amount of computing resources on the server. For large peer-to-peer network with millions of peers and billions of connections per day, a farm of address servers may be needed. This goes against the decentralization principles of such networks.
Address servers also add latency to the connection process. In a scenario of real-time communications and multimedia p2p applications, this is an undesirable property.
TCP Simultaneous Open
When both peers are behind NATs, the only way to “punch holes” in these NATs is by the application to send outgoing SYNs. This can only be achieved by using the TCP Simultaneous Open part of TCP, which is described in RFC793.
Port Prediction step
Methods to do port prediction
Because of the additional restrictions on TCP detailed in the sections above, an application cannot reuse the same mapping for all TCP sessions for the whole lifetime of the application. In particular, simultaneous TCP sessions will have to use distinct local endpoints and mappings.
We list 4 methods to perform port prediction based on various regularity properties that may be supported by the NAT:
- the NAT does TCP port preservation. In that case, the external port is the same as the internal port for each TCP mapping. There is no need to perform port prediction. The internal port information can be shared between the hosts via an arbitrary out-of-band communication channel.
- the NAT reuses the same mapping for successive connections coming from the same local endpoint. With that property, we can do the same thing as we did for UDP and perform port discovery with a STUN server (that we can call a STUNT server, for TCP)
- the NAT maps two successive local endpoint to external endpoints with the exact same distance between port numbers (we call this property TCP port delta preservation). With this property, the port discovery with a STUNT server needs only to be done once, and all successive mappings from other local endpoints can be guessed from the first one.
- the NAT uses the same scheme as (3), but only when the difference between port numbers is 1. This is sometimes called a delta+1 NAT. The application will proceed as in (3) to perform port prediction.
Any of these methods can be used for the port prediction step. Methods 2), 3), 4) need an address server, however methods 3) and 4) only need to use an address server once, and then external ports can be predicted for all subsequent TCP communications. Method 1) does not need require an address server at all.
An application needs to find out which schemes the NAT is supporting, if any, and use one or more schemes to perform the port prediction step. Once the port prediction step is done and the information is shared between hosts via an arbitrary third part communication channel, they are ready to proceed with the hole punching step proper through TCP simultaneous open.
Hole Punching step
Establishing the TCP connection
The previous step allowed us the acquire the remote endpoint of our counterpart. We can now proceed with the connection establishment by using a TCP simultaneous open. With enough collaboration from the NAT, this will work smoothly with any TCP stack supporting TCP simultaneous open (at the time of writing, virtually all OSes support this essential part of TCP), as shown below.
1. Host A and Host B both make a POSIX connect() system call to their counterpart at roughly the same time (not more than a few seconds difference). This results in the OS sending a SYN packet to the remote host.
2. Each outgoing SYN results in a new mapping being created in their respective NAT. Most of the time, one SYN reaches the other NAT before the mapping is created and is thus dropped by the other NAT. NAT should therefore drop incoming SYNs silently, as sending a RST segment would result in connection failure.
3. OS stacks re-send SYN segments on a regular basis for at least 3 times as long as the SYN+ACK is not received from the remote host. The timer typically implemented for resending SYNs is in the order of a few seconds. As a result, at some point incoming SYNs will be allowed through by the NAT.
4. One host, or both, will receive an incoming SYN, and send a SYN+ACK reply. Connection is established.
TCP hole punching only relies on the NAT not actively dropping incoming SYNs, for example by sending an RST segment back. The NAT needs to deny such TCP segments silently.
To sum up, TCP hole punching will work fine in the following circumstances:
- port prediction is done successfully
- the NAT passively drops incoming SYNs
Sometimes, the port prediction step may fail with low probability. This is the case especially with some port preserving mapping schemes since port preserving cannot be applied uniformly to all communications, since some collision cases may occur. When a collision happens, this results in an inaccurate port prediction step. We describe these cases in more detail below, and how an application deals with such cases:
Dealing with possible collision cases and connection failures
With port preservation or port delta preservation, it is not guaranteed that the predicted port number will be available. The port number may be already in use by another mapping. This occurs when the NAT becomes busier, especially when it does not use port overloading. In case of non-availability, the NAT will use a different port number. This is a collision event and results in the mapping scheme not being followed for this particular communication.
Collision events can happen with most mapping allocation schemes. We list below the conditions that can lead to possible collisions:
With port preservation schemes (1), (3), (4) of the previous section, collisions may occur when:
- the NAT does not use port overloading, and there is a collision between 3-tuples (source local endpoints)
- the NAT uses port overloading and there is a collision between 5-tuples (source endpoints and destination endpoints)
With the allocation scheme (2) of the previous section (with the help of an address server, in this scenario the application first connects to an address server, then to the remote host, hoping the NAT will reuse the same mapping for both connections). Collisions may occur when:
- the NAT uses port overloading, and the 5-tuple with the remote host is already in use in another mapping.
In collision cases, the port must be changed as a result of the port being already in use for some other session. This may result in a connection failure. If we assume that the probability of a collision is small, the application can deal with the failure case by retrying with a new binding. If p is the probability of a collision, the probability of success increases in (1-p^n) at each retry.
In general, P2P applications are prepared by design to deal with all sort of failure cases and NAT allocation schemes, as NAT behavior is not standardized and varies wildly across deployments.
Requirements on NATs to support hole punching protocols
General properties of the port allocation algorithm
Information and topology preservation
Preserving information included in port numbers or the topology of the network flows coming from an application is a general principle that does not only help interoperability for p2p applications but allows all sorts of applications to work behind NATs unhindered.
Since this is a relatively abstract principle, we explain it more details below and give some examples.
preserving information in port numbers
randomness
Regarding the choice of port numbers made by the application, the NAT should not introduce:
- more randomness: a random port allocation is not adequate if the host port allocation is not random, we loose information
- less randomness: don’t map a random internal port to a predictable external port. This defeats port randomization. See RFC 6056 for more information about port randomization.
parity
The NAT should try to preserve the parity of port numbers (port parity information is used by the some protocols)
deltas
The NAT should try to preserve the difference in port numbers from successive TCP connections coming from the same endpoint. A particular useful case is the preservation of deltas when the difference equals 1 (called delta+1 preservation).
port preservation
When the NAT uses a port preserving mapping scheme, all of the conditions above are automatically verified. This makes it an appealing scheme and relieves the NAT from having to make any decision in the choice of port numbers. However, with a preserving scheme collisions between mappings may occur (even when port overloading is used) so this nice property is not uniformly applicable to all communications, and in a collision case the NAT will have to choose a new port number on its own.
preserving topological properties of the application network flows
An application exhibits some topological properties in terms of network flows. For example, an application can use the same local endpoint to multiplex multiple udp communications, or initiate successive TCP connections from the same local endpoint.
In general, a NAT should behave as transparently as possible from the application viewpoint by mimicking the behavior of the application: the NAT should reproduce externally the properties of the network traffic it sees internally. However, preserving the topological properties of the application in terms of network traffic can be daunting in complex cases. At least, it requires the NAT to keep some additional state information about preserving about expired mappings and involves maintaining timers, timeout and mapping values. For complex topological properties, this task is clearly out of the scope of a NAT device, which is often a simple machine with limited computational resources that cannot be required to follow an intelligent behavior.
One property that we should require though is that a NAT should map packets coming from the same internal endpoint to a unique external endpoint. In other words, a NAT should “map a cone to a cone”, or a NAT should follow the “endpoint-independent mapping” scheme. This applies as long as the network flows are simultaneous or occur within a short period of time, such as 2 minutes. This is especially useful for UDP as previously explained and is often all an application needs. Such a behavior is easy to implement and greatly benefits p2p applications.
Regularity
Port prediction must be possible and work with high probability. It is not necessary to require port prediction to work all the time, deterministically, as it would prevent that NAT to implement other useful optimizations. For instance, it would prevent the NAT to do port overloading, which is a very useful thing to do for busy NATs in a CGN context. Applications are prepared by design to deal with a number of failure cases and a large variance in NATs behaviors and have fallback procedures in place already.
Any behavior where the NAT exhibits some regularity between mappings can be exploited by the application to perform port prediction and thus TCP hole punching.
Examples:
- allocating the same port to successive connections coming form the same internal endpoint. This can be leveraged to perform port prediction (although with all the caveats that come with using the SO_REUSEADDR option on TCP sockets).
Formalised Requirements
Mapping allocation schemes
REQ 1: For UDP, the NAT MUST use an endpoint-independent mapping scheme (the NAT must “map a cone to a cone”). The state associated with each of such “cones” must be preserved for a least 2 minutes every time after an outgoing packet is seen coming from the originating endpoint.
Justification: It is known that many applications rely on this feature when it is available. Applications possibly use other regularity properties of the NATs allocation algorithms, however for UDP this property seems to be the most convenient of all to use.
REQ 2: For TCP, the NAT SHOULD use all or some of the following mapping schemes:
– port preserving
– delta preserving, or delta+1 preserving
– sharing the same mapping for successive connections originating from the same endpoint (a weaker requirement than endpoint-independent mapping, since it does not require simultaneous flows coming from the same endpoint to be mapped to the same external endpoint)
– endpoint-independent mapping, the same as for UDP in REQ 1 above
Justification: the NAT should have as many regularity properties as possible in its allocation algorithm to support different methods of port prediction. In the event of a busy NAT that does not use port overloading, some allocation schemes may fail for some communication. An application must be prepared to deal with all cases of failure and a variety of NAT behaviors.
NOTE 1: A NAT MAY use a port overloading scheme for TCP.
Justification: This is especially beneficial to busy NATs. It reduces the probability of collision when the NAT uses a TCP port preserving mapping scheme to essentially 0. Since 5-tuple uniqueness is preserved by port overloading, there are no significant shortcomings to using such scheme.
Filtering schemes
REQ 3: The NAT MUST passively deny incoming packets that are not part of an existing session
Justification: For security reasons, the NAT must deny packets not part of an existing session. NAT must passively (silently) drop SYN packets to avoid interfering with hole punching and tcp simultaneous open.
The rest of the requirements is not directly related to p2p applications, instead, they are generally applicable. We give them for informational purposes:
UDP mapping refresh
REQ 4a: UDP mappings corresponding to inactive network flows MUST NOT expire before 2 minutes. Only outbound packets can refresh a mapping.
Justification: There needs to be a timeout value to expire inactive NAT mappings. Although 2 minutes is an arbitrary value, having a keepalive packet sent by the application once every two minutes seems reasonable. Only outbound packets should be considered to refresh a mapping timer, as they clearly state the intent of the application, as opposed to inbound packets that could be sent by an attacker.
TCP mapping termination
REQ 4b : TCP mappings corresponding to inactive network flows SHOULD NOT expire before 2 hours and 4 minutes
REQ 4c: TCP mappings in closing process (after FINs have gone through in both directions) MUST NOT expire before 4 minutes
Justification: 4b: This is simple compliance with TCP. However, a reasonable application knows that an inactive mapping may be deleted if the NAT is busy, so will send keepalives more often than the recommended 2 hours value.
4c: TIME_WAIT must be granted by the NAT to ensure proper connection closure in case the FIN must be re-sent.
Support for hair-pinning
REQ 5: NAT MUST support hair-pinning scenarios